Get Started With Kubernetes
This guide goes into the details about using Reliably in a Kubernetes context.
Reliably can use your Kubernetes ecosystem in two fashions:
- Target Kubernetes from your experiments. In this case, your use Reliably to perform actions against your Kubernetes clusters in a Chaos Engineering way.
- Use Kubernetes to run Reliably Plans. In that case, Reliably schedules its plans to run from a Kubernetes cluster. Experiments carried by these plans do not necessarily target a Kubernetes cluster itself. Here, Reliably orchestrates plans by using your cluster as a distributed workload system.
These two modes can work together, meaning you can run a Reliably experiment that target the cluster on which the experiment is being executed on.
Kubernetes as a Target System for Experiments
Reliably offers a large set of actions and probes focused on Kubernetes.
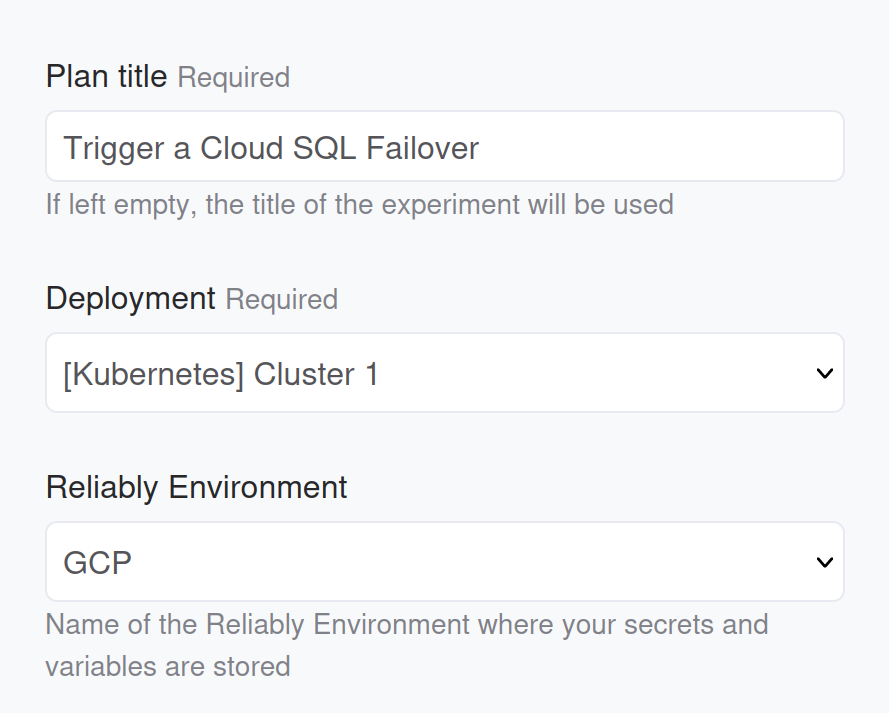
Once you have put up together an experiment that you are happy with, you can run it against your Kubernetes cluster via a Reliably plan. When setting up the plan, you only need to select an Environment that declares environment variables and secrets allowing Reliably to connect with the Kubernetes API server.
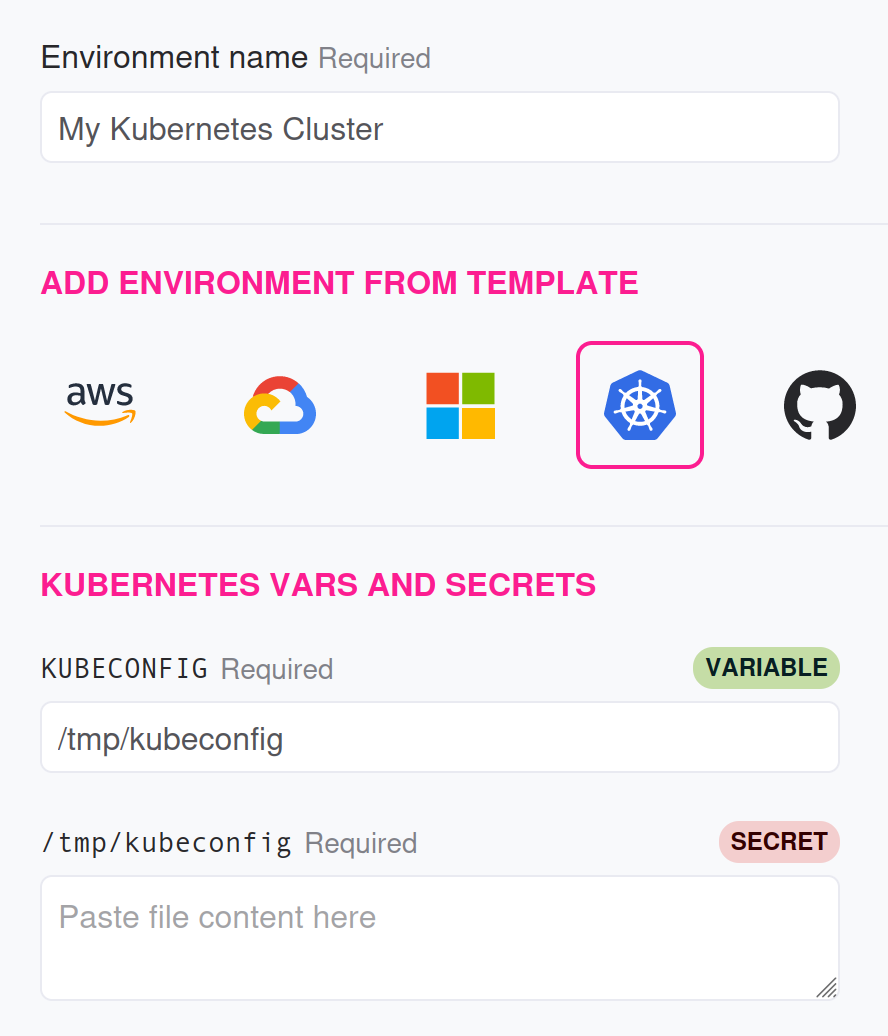
When you create the plan to run an experiment targeting a Kubernetes cluster, make sure to select the correct environment so Reliably knows how to connect and authenticate with the Kubernetes API server.
Make sure to give the service account the right RBAC for the experiment. For instance, if the experiment needs to delete a pod, make sure the service account is associated with a role that has that permission.
Distribute Reliably Plans on Kubernetes
Running Reliably Plan can occur on your Kubernetes cluster instead of from Reliably Cloud. To do so, you must create a Deployment and use it when creating a Reliably Plan.
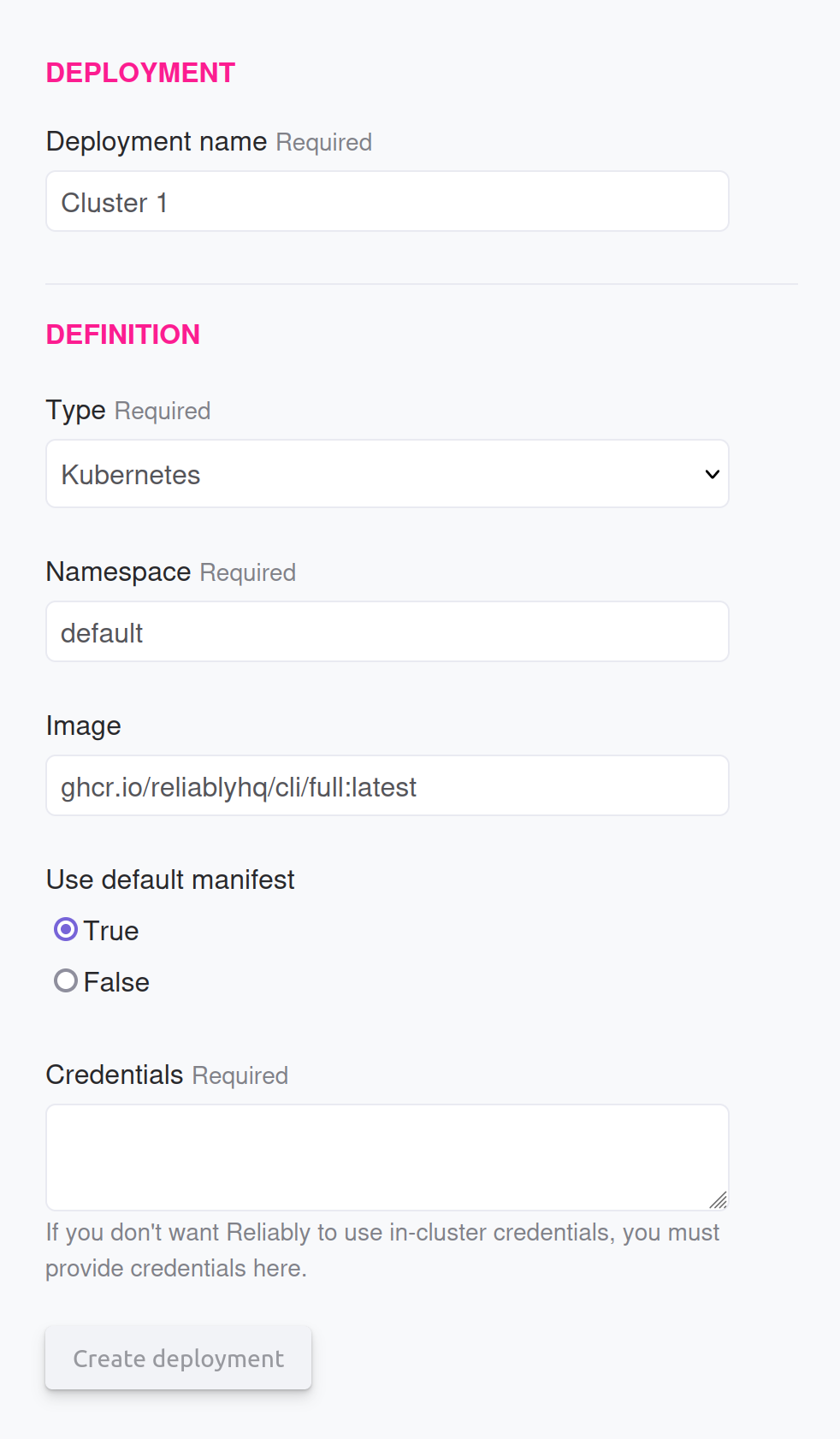
The container image needs to use the Reliably CLI as its entrypoint so Reliably can invoke it to execute the plan.
The credentials are passed as a service account which requires the roles to create Kubernetes Job and/or Kubernetes CronJob.
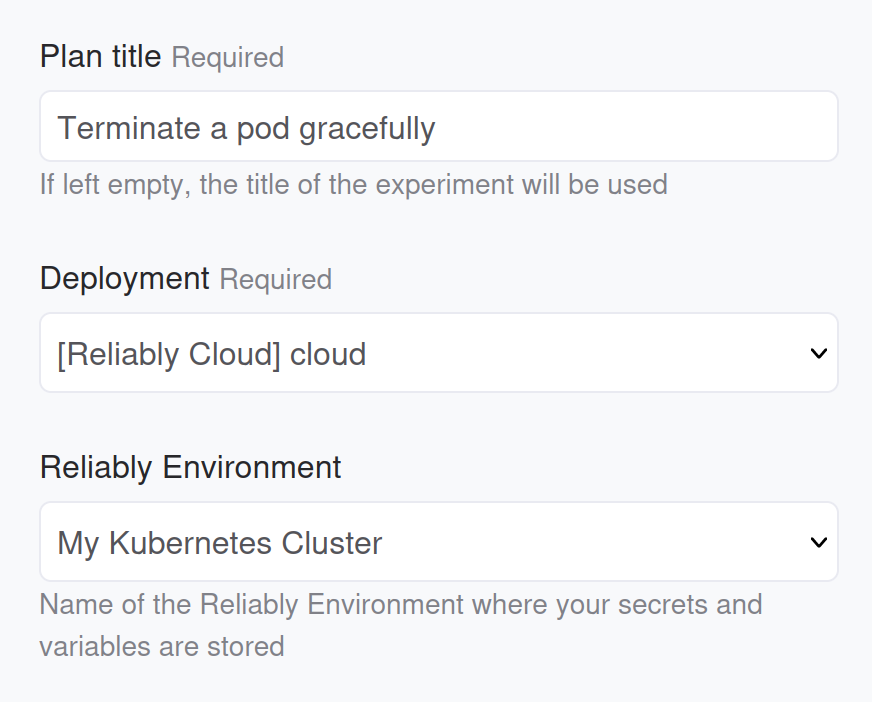
Once created, you can schedule Reliably plans onto that cluster:
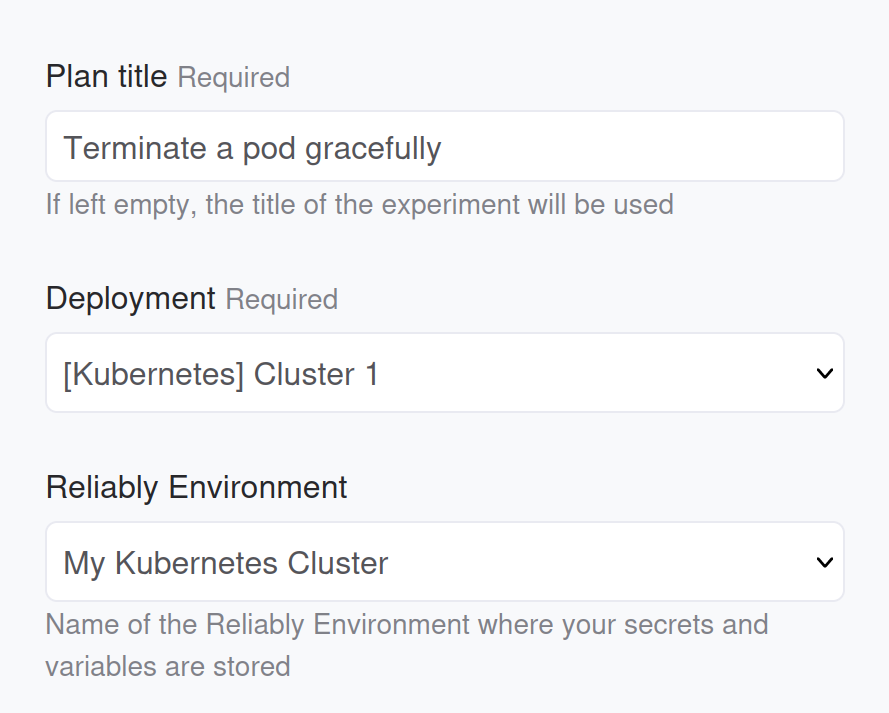
Notice how we also selected the Kubernetes environment from the previous section. This is only required if the experiment we are scheduling is targeting itself a Kubernetes cluster. Of course, you can run experiments that target any platform: