What Does It Mean To Build Resilient Service Applications?

5 minutes

What is resilience?
Resilience is the capability to recover quickly from difficulties or toughness. It is not about preventing failures, but being able to recover from them quickly.
As Amazon’s CTO Werner Vogels famously said ‘everything fails all the time’.
It’s a fact of life that failures will inevitably happen but what we can do is build applications that can withstand different kinds of failures.
For example, in a data center, hardware is going to fail all the time. In order to withstand hardware failure, we could run applications on multiple servers. If one server goes down, the system continues to work.
Expecting the unexpected

Even when we take steps to build resilience, the unexpected could happen. A data center could go down in some exceptional circumstances like storm clouds.
There was one instance when a shark bit one of the underwater cables which broke down some of the network capabilities in the data centers for Google. Google engineers probably didn’t account for something like that to happen. You never know what to expect.
The best solution is to run applications across multiple availability zones or multiple regions so that when one of the availability zones or regions goes down applications can recover quickly by routing traffic to the remaining active regions.
Since the individual servers have a limited set of resources in terms of how much CPU or memory or bandwidth it has, the more user requests that it handles concurrently, the more resources we’re going to end up using.
This is a very common failure when there are just too many requests hitting the same server at the same time as it causes saturation for either the CPU or the network bandwidth. The latency will start to spiral out of control which is another reason why we need to be able to scale out our application across multiple servers. As a result, we achieve a distributed environment where services often have to call other services.
If one of the other services goes down then we get a cascade of failures across the entire system so that eventually the user is going to try to do something and they’re going to get the firewall tool and this will not make customers and users happy because they’ll be met with interruptions.
Four Areas Of Resilience
This diagram from Uwe Friedrichsen highlights the four broad areas that we should consider when we think about resilience.
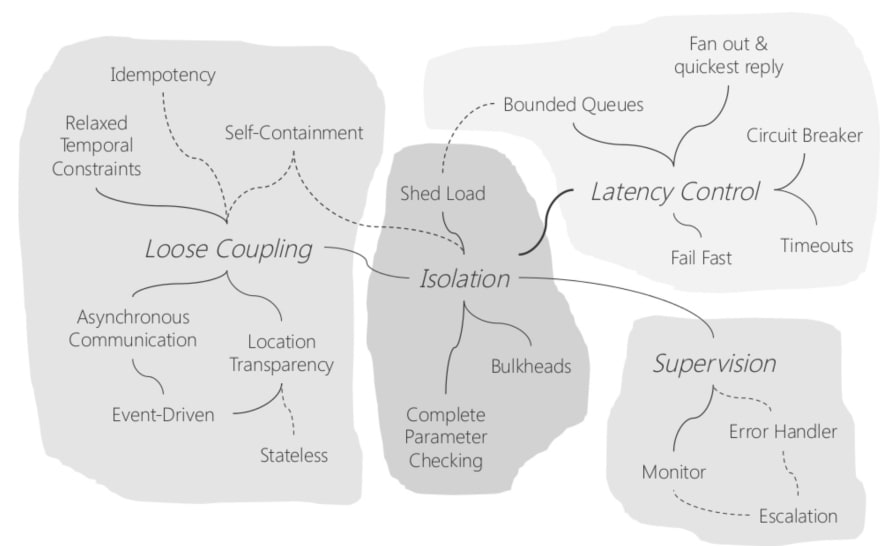 Source:
Source: The four areas of resilience are:
- Loose Coupling
- Isolation
- Latency Control
- Supervision
Reliability and Resilience
Enterprise businesses spend a lot more time thinking about resiliency proactively, compared to startups which typically focus on getting things done as quickly as possible and take a much more reactive approach.
The cost of downtime is not as significant compared to a large enterprise (especially financial institutions like banks). Their downtime can lose them millions of dollars by the minute and so it is important to look at different contexts.
Chaos engineering is getting lots of attention nowadays because big enterprises recognize that the cost of downtime is significant.
It makes sense for banks to invest heavily into better resiliency. Even if it means going from 99.9 to 9.999 -which is a huge investment for a lot of these companies- it’s worth it. It is not just a technical issue it has to be something that starts with building a culture of reliability as well.
Lambda Execution Environment

Lambda automatically provides an out-of-the-box resilience solution because there is an isolated execution environment for each invocation.
Therefore, if one user request uses up too much CPU or memory, it does not affect any other concurrent user requests.
This is very different from running applications on an EC2 server where all the concurrencies are being handled by code, running on the same machine and sharing the same resources. In this situation, unlike with Lambda, when one user request uses up too many resources, it has an impact on everybody else.
Benefits of the Lambda Execution Environment
The key benefits of Lambda are:
- Multiple AZs out of the Box
- Load Balancing
- Data Replication in different AZs
- Built-in throttling
1. Multiple AZs out of the Box
When you build APIs with an API gateway and Lambda, you also get multiple AZs out of the box. This occurs because the API gateway and Lambda deploy your functions and API across three different availability zones by default, ensuring that you do not have to do anything to acquire resilience against one data center going down.
One data center will not take your app down, and both API Gateway and Lambda will charge you based on usage, so you only pay when the user uses your system.
This is great for those low throughput environments where you do not have to run loads of servers across multiple availability zones and waste a lot of CPU cycles that you just do not end up using.
2. Load Balancing
You also gain load balancing out of the box when an HTTP request comes into API Gateway or Lambda. The request will be routed to one of the availability zones meaning you do not have to configure anything yourself.
3. Data Replication in different AZs
DynamoDB provides you with multi-AZ by default and will replicate your data across multiple availability zones within the same region.
To get the gold standard for building resilient APIs and AWS, you can configure your DynamoDB tables as global tables so that the data can get replicated across multiple regions - turning your whole API into this multi-region active-active setup.
4. Throttling
Getting a lot of resilience when using serverless technologies like API gateway, Lambda, and DynamoDB is invaluable, however, there is always a need to be careful, which is why throttling is useful.
When a user request comes in, it will hit the API Gateway, which triggers a Lambda function, which will talk to a DynamoDB table. At each point along this call chain, there will be some built-in throttling that AWS enforces. It’s important to make sure that all of the timeout limits and throttling is aligned correctly for your service.