Build and scale your resilience engineering capability
Reliably helps you tackle incidents and cost overruns, to build more reliable products with more confident and healthier teams.
The delta between project objectives and implementation is costly and painful.
Failure surface area
How much of potential issues do you discover before they happen in production?
Decision Impact Projection
You know how much you are spending on your infrastructure. But what if you could evaluate how reducing costs impacts your bottom line and SLOs?
Evaluation of Operations Effectiveness
You have monitoring, observability, and paging tools deployed, but how confident are you that they would work as expected should an incident happen?
Reliably enables you to develop a strong reliability engineering
capability, supporting your teams in delivering more dependable products
on time and within budget.
Simplify building valuable experiments
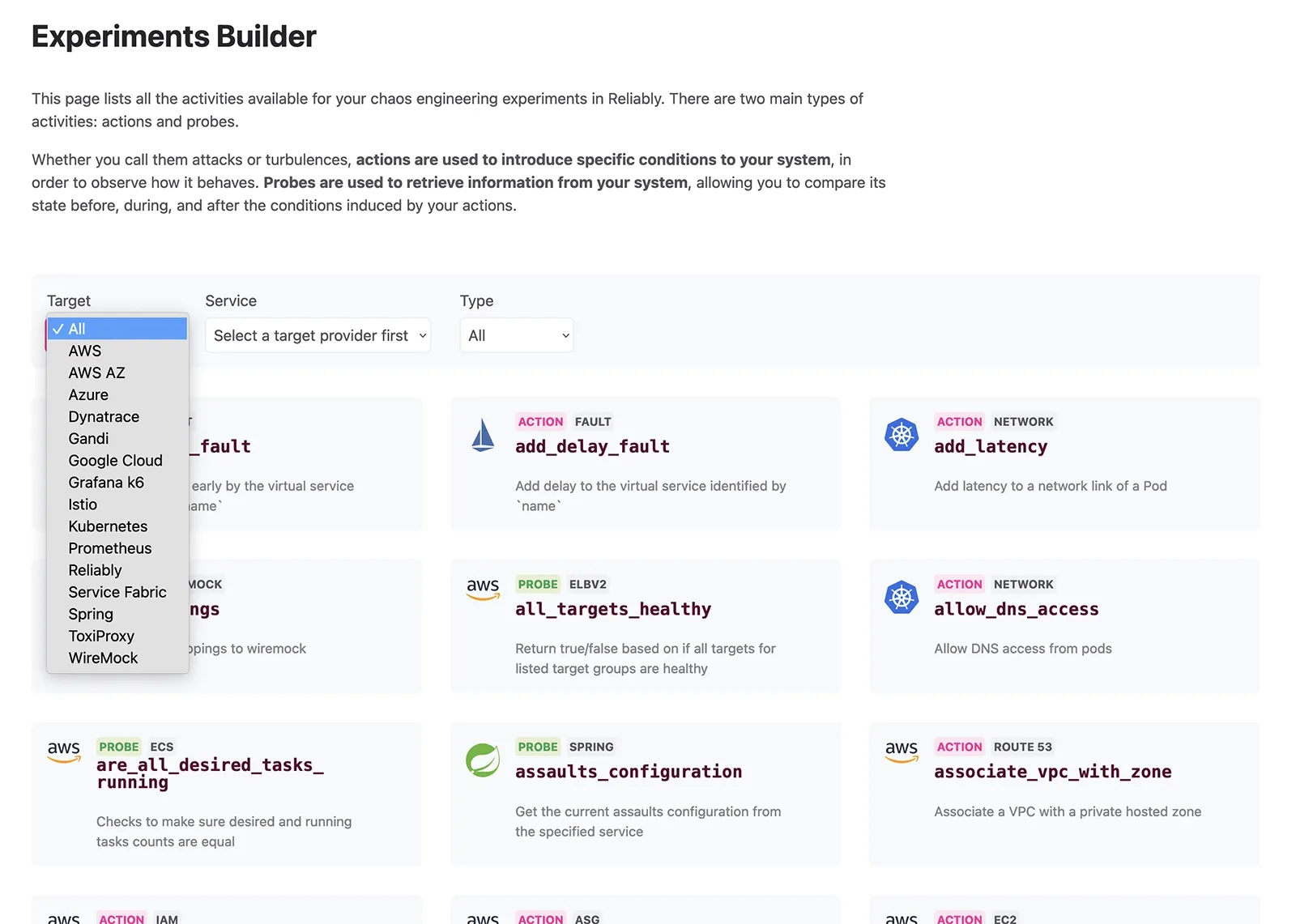
Reliability engineering hinges on the art of experimentation—whether it's peering into the unknown or validating expected outcomes. The Reliably Experiment Builder simplifies experiment creation and introduces a novel way to visualize your workflow.
Addressing two pivotal challenges faced by early champions looking to expand reliability practices within their organizations, our Experiment Builder eliminates the need to learn a new «language» for crafting experiments and significantly accelerates the onboarding process for teams and users.
The Reliably Experiment Builder provides an arsenal of over 300 actions, from «attacks» to probes, enabling you to construct experiments of any complexity with ease.
Quickly discover where you're at risk
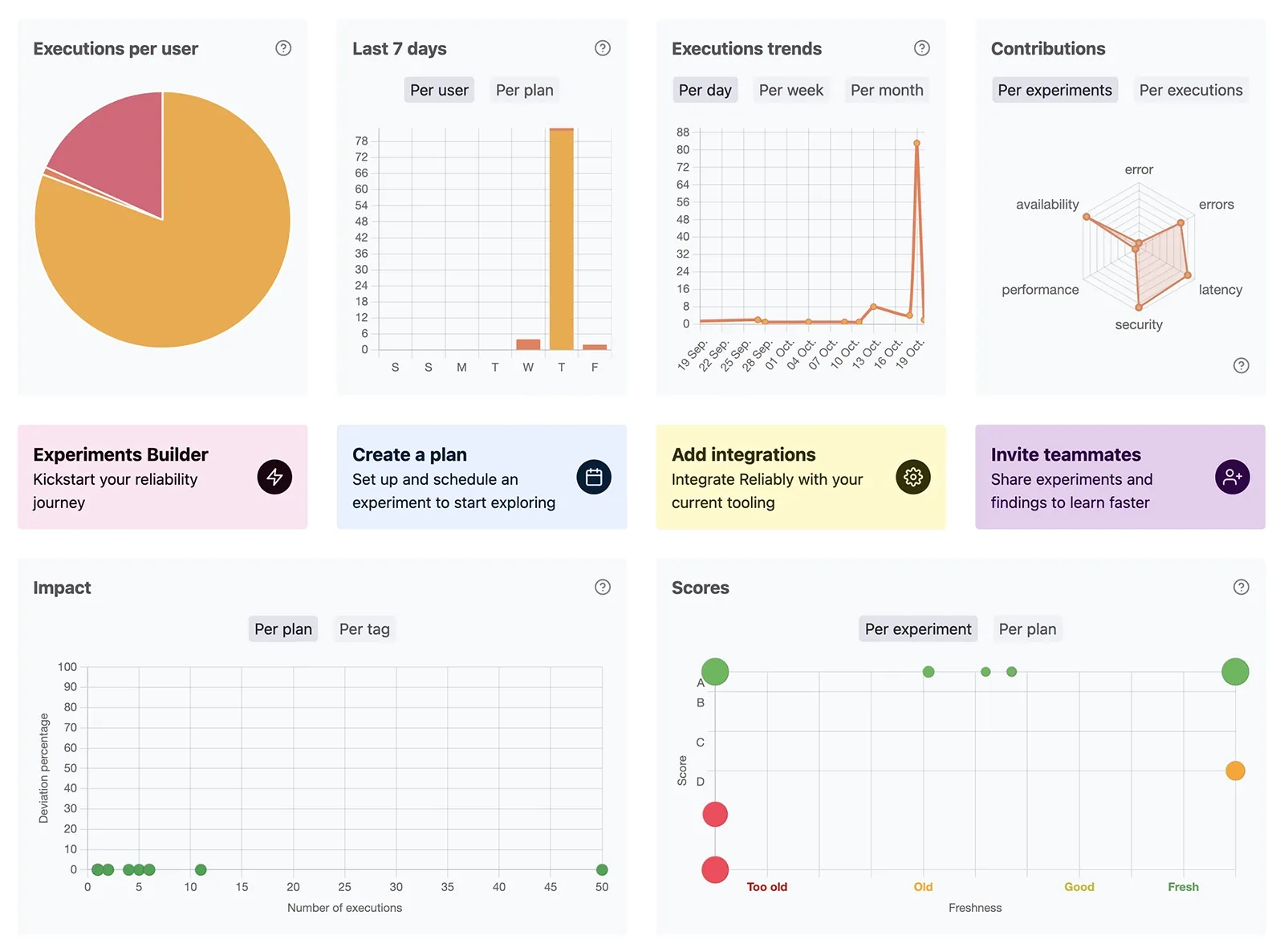
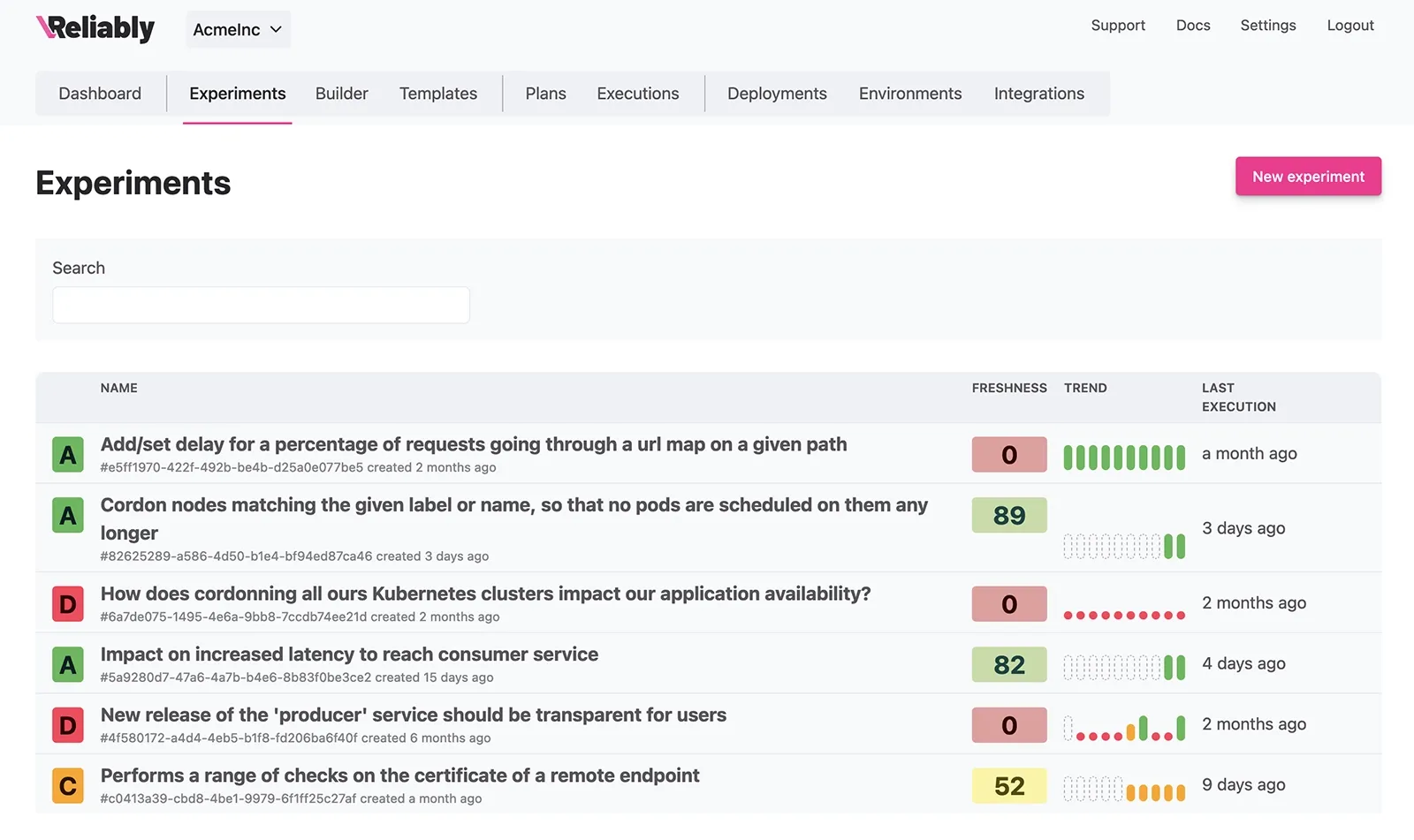
Reliably empowers software engineers with a suite of tools designed to enhance their reliability initiatives. Whether you're tracking the execution journal or assessing your organization's overall progress, we've got you covered.
The timeline takes the execution journal to a whole new level of user-friendliness. It enables you to monitor results for each activity in real-time as they unfold.
Leverage the score and freshness indicators to assess the performance of your services and identify areas where more effort is needed.
The Reliably dashboard serves as your strategic vantage point for gaining valuable insights into your organization's reliability engineering efforts. Dive into trends, assess impacts, scrutinize scores, and evaluate contributions from a single, high-level perspective.
As versatile as your system requires
Ensuring widespread adoption of resilience engineering practices within your organization requires aligning your tools with the diverse needs and preferences of all your teams and developers. Reliably is designed to seamlessly integrate into a wide range of systems, and operates across various platforms, from your preferred CI/CD pipelines to the cloud.
With over 300 distinct activities at your disposal, Reliably empowers you to effectively target AWS, Azure, Google Cloud, Kubernetes, Prometheus, Spring, and more.
You can execute experiments through popular CI/CD providers like Jenkins, Travis, or CircleCI, as a GitHub Action, or directly within the Reliably Cloud, including a Private SaaS option for enhanced data security. For those seeking even greater control, Reliably offers the flexibility of on-premises deployment within your existing infrastructure. And it even runs on your machine.
Reliably is the only chaos engineering solution that fulfills our requirements in terms of security and pricing.
Features The Reliability Platform
Reliably helps organizations of all sizes deliver more reliable products.
- Experiment builder
- Reusable experiment templates
- Import JSON Chaos Toolkit experiments
- Run from your CI/CD, in the cloud, or on-premises with Docker or Kubernetes
- Schedule executions
- Over 300 attacks and probes
- Target AWS, Google Cloud, Azure, Kubernetes, and more
- Explore and learn with the execution timeline and dashboard
- Native integrations with Honeycomb, Grafana, Slack, and more
- Built on top of Chaos Toolkit, the developer-favorite open source chaos engineering toolkit
Ready to get started?
Start better understanding how your system works, to make it more reliable and easier to debug.
Create your free account now (no credit card required) and you will be running experiments in minutes.
10-minute starting guide
Whether you're already using Chaos Toolkit or not, you could be sending data to Reliably in minutes (for free).